

Every organization depends on documents.
Contracts define commercial relationships. Vendor agreements define obligations. Regulatory documents define compliance requirements. Product specifications define delivery expectations.
Yet one of the most expensive and time-consuming activities across enterprises remains surprisingly manual: Understanding what changed between document versions and determining whether those changes actually matter.
Traditional comparison tools highlight differences. They do not understand significance. A procurement director reviewing a revised Master Services Agreement does not care that a page break moved. They care that:
- Liability caps changed
- SLA commitments changed
- Pricing terms changed
- Data privacy obligations were added
- Termination clauses were modified
At Nirvana Lab, our work in digital transformation informs how we approach intelligent document workflows — making human-review processes faster, more traceable, and genuinely actionable.
Compare an old document and a new document and tell me what changed.
Why We Started Building This
The original requirement sounded deceptively simple:
Anyone who has worked with enterprise documents knows that this is significantly more difficult than it appears. During discussions with procurement, legal, and compliance stakeholders, we repeatedly heard the same concern:
"We spend hours reviewing revised documents and still worry that we may have missed something important."
The issue was not finding differences. Existing tools already do that reasonably well. The issue was understanding:
- Which differences matter
- Why they matter
- Who should review them
- What action should be taken
That realization fundamentally changed our perspective. We were not building a comparison tool; we were building a decision-support system.
Comparison Versus Intelligence
Before we built anything, we had to articulate the fundamental difference between what traditional tools do and what we needed to create.
Traditional comparison answers: What text changed?
Our AI-powered Document intelligence answers: What changed, why does it matter, and who should care?
| Change | Business Impact |
|---|---|
| Header formatting modified | None |
| Section moved to another page | None |
| Notice period changed from 30 to 90 days | High |
| New liability clause added | High |
| SLA availability changed | High |
| Privacy obligations introduced | High |
This distinction is what transforms a document diff tool into a genuine decision-support system.
A Real-World Scenario: Vendor Contract Review
To make this concrete, consider a procurement team that receives a revised 180-page Master Services Agreement from a strategic software vendor.
The team needs answers to questions such as:
- Did liability limits change?
- Were new privacy obligations introduced?
- Did SLA commitments change?
- Were termination clauses modified?
- Did pricing or renewal terms change?
Traditional PDF comparison tools might return hundreds or thousands of differences. The procurement director does not want 1,200 differences. They want 7 meaningful findings. That became our guiding principle.
Why We Didn't Just Send Everything to GPT
One of the first questions executives ask is:
Why not simply upload both PDFs into GPT and ask for a summary?
While attractive initially, this approach introduces several challenges:
- Hallucinations
- Limited explainability
- Context window constraints
- Weak auditability
- Lack of page-level traceability
- Higher operating costs
This led us to a simple design philosophy:
Deterministic systems discover facts. AI systems explain meaning.
High-Level Architecture
The platform is built on two complementary layers:
- The deterministic layer produces evidence.
- The AI layer produces understanding.
Applying Semantic Diffing for Document Comparison
What is semantic diffing?
Traditional diffing compares text. Semantic diffing compares meaning.
In business documents, this distinction is critical. A formatting change is usually not important. A change from "effective after 30 days" to "effective after 90 days" is highly important. A section that moves from page 12 to page 15 may not matter. A new exclusion or liability clause added inside that section may materially impact obligations.
The Document Comparison Agent first generates raw diff operations from the old and new documents. These raw operations include inserted text, deleted text, modified nodes, page ranges, and table row differences. The semantic analyzer then uses those raw operations as hints, not as final truth.
This is important: raw diffs are useful evidence, but they are not always business meaning. The semantic layer reviews old and new page content holistically and determines whether a real document change exists.
Use cases of semantic diffing in document intelligence
Semantic diffing enables several high-value document workflows across industries:
- Contract and policy change detection – Identify changes in limits, exclusions, benefits, coverage rules, deadlines, and claim conditions.
- Renewal comparison – Compare expiring and renewed document versions to detect business-impacting changes.
- Regulatory review – Highlight changes that may require compliance validation.
- Stakeholder impact analysis – Explain how a revision affects the party bound by the document.
- Email-driven automation – Allow users to send old/new links or attachments by email and receive a structured report automatically.
- Batch document review – Compare multiple document pairs in one job and send one consolidated report.
The result is not just a technical diff. It is a business-readable interpretation of document changes. Each reconciled change becomes a structured record — with category, significance, title, page range, and linked raw diff evidence for audit traceability.
Building the End-to-End Architecture
Key components of an AI-powered document comparison agent
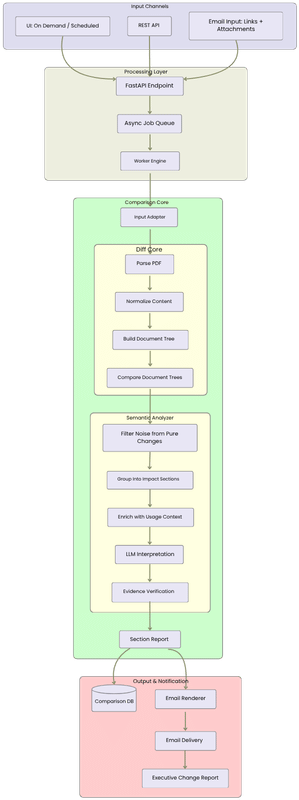
The Document Comparison Agent follows a decoupled backend architecture designed for enterprise usage.
The major components are:
FastAPI Endpoint Layer
Accepts requests from UI, API clients, scheduled jobs, and email ingestion flows.
Input Adapter
Normalizes different input modes such as uploaded PDFs, local file paths, URLs, batch pairs, and email-extracted attachments.
Async Job Queue
Decouples request submission from long-running comparison work. This keeps the user-facing API responsive.
Worker Engine
Processes jobs asynchronously and executes the comparison pipeline.
Diff Engine
Parses PDFs, extracts text/tables/layout, builds structured document representations, and generates raw diff operations.
Semantic Analyzer
Groups raw changes into review bundles, enriches them with page context, runs LLM reconciliation, verifies evidence, consolidates duplicates, and generates summaries.
Email Renderer and Delivery Service
Sends a consolidated report with job metadata, pair-level results, material/non-material counts, and executive summaries.
Database Tracking Layer
Stores comparison execution status, timestamps, inputs, and structured JSON output for traceability and UI visibility.
The diff engine runs a deterministic five-stage pipeline: parse documents → normalize extracted content → build document tree → compare trees → assemble diff result.
Integration with existing enterprise workflows
The agent supports multiple real-world operating models.
UI-driven execution
Business users can submit an on-demand comparison or configure scheduled comparisons from the UI.
Email-triggered execution
Users can send an email with old/new document links or old/new PDF attachments. The parser extracts pairs, validates rules, and creates comparison jobs.
API-based execution
Other enterprise systems can call the comparison APIs directly using files or URLs.
Scheduled execution
A scheduler can periodically trigger configured document comparisons and track each execution in the database.
This flexibility is important because document review rarely happens through a single channel. Some teams work through portals. Some receive revisions through email. Some need automated recurring checks. The architecture supports all of these without duplicating the comparison engine.
Detecting Material vs Non-Material Document Changes
Defining material and non-material changes
A key goal of the Document Comparison Agent is to separate changes that matter from changes that merely create noise.
Material changes are changes that may affect document interpretation, obligations, exclusions, eligibility, claim behavior, legal wording, pricing, benefits, limits, deadlines, or stakeholder impact.
Non-material changes include formatting changes, rewording without business impact, metadata updates, layout shifts, minor spelling corrections, or section movement that does not change meaning.
The semantic analyzer is intentionally conservative with business meaning. It keeps changes involving obligations, exclusions, numeric thresholds, percentages, caps, conditions, deadlines, or legal wording. At the same time, it is designed to ignore formatting-only differences caused by PDF extraction, line wrapping, page layout, or numbering shifts.
Examples and their impacts on compliance and operations
A raw diff may show many textual changes. The semantic analyzer turns them into a smaller, cleaner set of business changes.
For example:
- Changing “30 days” to “90 days” in a notice period is material.
- Adding a new exclusion or liability clause is material.
- Reordering sections without changing clause meaning is non-material.
- Updating a revision date may be non-material unless it signals a new effective period.
- Changing a phone number or formatting a header is usually non-material.
- Modifying a threshold, limit, percentage, condition, or requirement is material.
| Change Type | Definition | Examples | Impact |
|---|---|---|---|
| Material | Alters obligations, benefits, limits, exclusions, conditions, legal meaning, or stakeholder rights | Notice period changed from 30 to 90 days; new liability clause added; benefit cap reduced | Requires legal, compliance, underwriting, or operations review |
| Non-Material | Does not alter document meaning | Formatting changes, typo fixes, section reordering, repeated header/footer changes | Logged for audit but usually does not need escalation |
| Conditional | Depends on document context or threshold | Threshold change for a specific plan, geography, rider, or category | May require business review depending on domain rules |
| Regulatory | Introduced due to legal or compliance requirement | Updated privacy clause, mandated disclosure, jurisdiction-specific wording | Must be tracked and explained clearly |
| Noise | Caused by PDF extraction, OCR, layout shift, or line wrapping | Broken sentences, page number shifts, table alignment issues | Filtered out by deterministic cleaner and semantic reconciliation |
Implementing the System: Tools and APIs
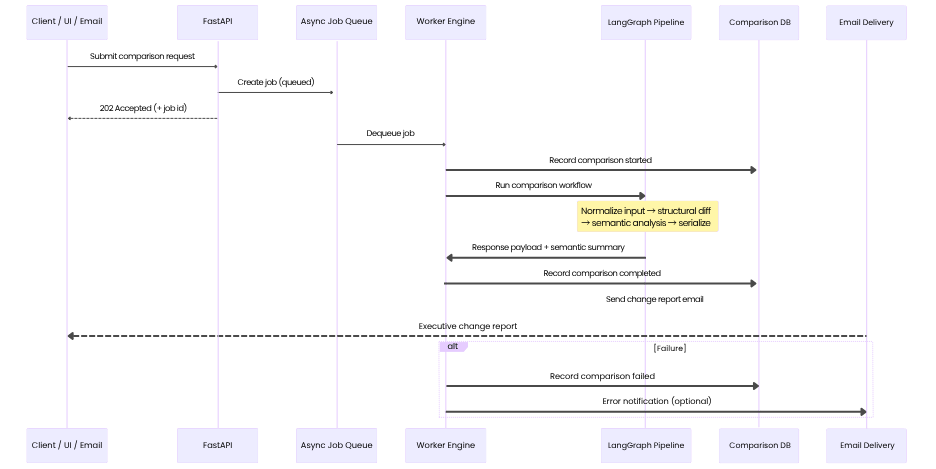
Using LangGraph with Python and FastAPI
The implementation uses FastAPI for the API layer and LangGraph for orchestration. The comparison work is handled asynchronously so the API does not block while large PDFs are parsed, compared, and summarized.
The semantic analyzer runs as a two-stage pipeline — first deterministic filtering, then page-aware LLM reconciliation:
# Step 1: filter noise from raw diff operations
filtered_changes = filter_noise_from_raw_changes(raw_changes)
# Step 2: reconcile meaning page by page and produce final summary
summary = await reconcile_and_summarize(
old_document=old_document,
new_document=new_document,
filtered_changes=filtered_changes,
)
return summary
Review bundles are grouped by old/new page-pair signature so related changes on the same pages are reconciled in one LLM pass. The full semantic reconciliation flow:
- Build review bundles from cleaned raw diff operations.
- Compact bundles to reduce unnecessary LLM calls.
- Enrich bundles with old and new page content.
- Run one LLM reconciliation pass per bundle.
- Normalize outputs into semantic change objects.
- Verify candidate changes against compact raw diff hints.
- Consolidate duplicate or overlapping changes.
- Generate executive and stakeholder impact summaries.
This pattern is powerful because it avoids sending the entire document to the LLM at once. Instead, it sends focused page bundles with relevant raw diff hints. That improves cost, accuracy, and scalability.
API design for document comparison workflows
The API supports file upload, URL comparison, batch comparison, and email ingestion. Endpoints and field names below are illustrative — the important pattern is a small, consistent REST surface that accepts document pairs asynchronously and returns a job identifier for tracking.
curl -X POST https://api.example.com/v1/comparisons \
-F “baseline_document=@previous-version.pdf” \
-F “revised_document=@current-version.pdf” \
-F “change_preview_count=20″ \
-F “include_detailed_diff=false” \
-F “notify_by_email=true”
# Compare two document URLs
curl -X POST https://api.example.com/v1/comparisons \
-F “baseline_url=https://example.com/previous-version.pdf” \
-F “revised_url=https://example.com/current-version.pdf” \
-F “change_preview_count=20″ \
-F “notify_by_email=true” \
-F “comparison_name=Contract A”
# Run batch comparison for multiple document pairs
curl -X POST https://api.example.com/v1/comparisons/batch \
-H “Content-Type: application/json” \
-d ‘{
“comparisons”: [
{
“baseline_url“: “https://example.com/previous-v1.pdf“,
“revised_url“: “https://example.com/current-v1.pdf“,
“correlation_id“: “cmp-001”,
“comparison_name“: “Contract A”
},
{
“baseline_url“: “https://example.com/previous-v2.pdf“,
“revised_url“: “https://example.com/current-v2.pdf“,
“correlation_id“: “cmp-002”,
“comparison_name“: “Contract B”
}
],
“change_preview_count“: 20,
“notify_by_email“: true
}’
# Ingest an email containing document links or attachments
curl -X POST https://api.example.com/v1/comparisons/email \
-F “message=@sample-message.eml”
For email-driven comparison, messages must follow old-to-new pairing rules. Link labels are configurable so the parser can reliably match baseline and revised versions, for example:
NEW_VERSION_LINK_LABEL=View Current Version
This makes the email parser deterministic and avoids accidentally comparing the wrong document versions.
Future Scalability and Enterprise Considerations
Replace in-memory queue with Redis, Kafka, or cloud queue service
This improves reliability, retry behavior, and horizontal worker scaling.
Add dead-letter queues and retry policies
Failed comparisons can be retried or routed for human investigation.
Introduce Temporal or workflow orchestration
Long-running document comparisons can become durable, observable workflows.
Separate parsing, diffing, semantic analysis, and reporting workers
Different workloads can scale independently.
Add real-time progress updates
UI users can see status such as queued, parsing, diffing, analyzing, summarizing, completed, or failed.
Add analytics over JSONB diff results
Organizations can analyze trends in document changes, material change frequency, vendor behavior, or compliance impact.
Design considerations for enterprise AI adoption
Moving from prototype to production requires more than good prompts. Enterprise AI systems need governance, reliability, and operational control.
Important design considerations include:
- Evidence-first AI – LLMs should interpret and summarize, but outputs should be verified against raw diff evidence.
- Prompt guardrails – The semantic analyzer should explicitly reject unsupported changes and avoid inventing document meaning.
- Traceability – Store raw diff hints, semantic changes, page ranges, and summary metadata for audit.
- Multi-tenant isolation – Tenant-specific inboxes, sender identities, notification recipients, and comparison configs should be isolated.
- Async execution – Long-running document intelligence tasks should run in workers, not inside request threads.
- Config-driven behavior – Email labels, recipients, scheduled comparisons, and tenant settings should be configurable.
- Cost management – Bundle compaction, raw hint truncation, chunking, and final summarization help control LLM usage.
- Human review readiness – Material or uncertain changes can be routed to legal, compliance, or domain expert teams.
The best enterprise AI architecture combines deterministic systems with LLM reasoning. In this Document Comparison Agent, deterministic parsing and diffing produce evidence. LLMs interpret meaning. Verification checks whether the interpretation is supported. Consolidation removes duplicates. Summaries make the results consumable for business stakeholders.The best enterprise AI architecture combines deterministic systems with LLM reasoning. In this Document Comparison Agent, deterministic parsing and diffing produce evidence. LLMs interpret meaning. Verification checks whether the interpretation is supported. Consolidation removes duplicates. Summaries make the results consumable for business stakeholders.
If your organization is exploring AI-powered document intelligence or agentic workflows, Nirvana Lab can help. Our teams specialize in building enterprise-grade solutions that combine deterministic precision with AI-driven insight. Contact us to start a conversation.
Summary
In summary combining LangGraph orchestration, structural PDF diffing, semantic reconciliation, evidence verification, async processing, and email-driven automation creates a powerful next-generation Document Comparison Agent. It helps organizations move from manual document review to automated document intelligence, where material changes are detected faster, false positives are reduced, and business teams receive clear executive-ready reports.
Frequently Asked Question
What is an AI document comparison agent?
An AI document comparison agent is a system that compares old and new versions of a document, detects differences, interprets their business meaning, and generates structured reports for technical and business users.
Why is traditional PDF comparison not enough?
Traditional PDF comparison detects formatting and extraction differences as changes. Business documents require semantic analysis because small wording changes can alter obligations, exclusions, limits, or conditions.
How does LangGraph help?
LangGraph orchestrates each workflow step as a node — input adaptation, diff generation, semantic analysis, and serialization — with shared typed state.
What is semantic diffing?
Semantic diffing compares meaning rather than raw text, distinguishing material changes from formatting noise.
How does the system reduce hallucinations?
Candidate LLM changes are verified against compact raw diff hints; unsupported changes are rejected.
What are material changes?
Changes affecting obligations, exclusions, limits, benefits, conditions, legal wording, deadlines, or stakeholder rights.
Can the system process emails?
Yes — users send old/new links or PDF attachments; the system parses pairs, runs comparison, and sends a consolidated report.
Can this architecture scale?
Yes — from in-memory queue to Redis/Kafka, distributed workers, Temporal workflows, real-time status, and analytics dashboards.