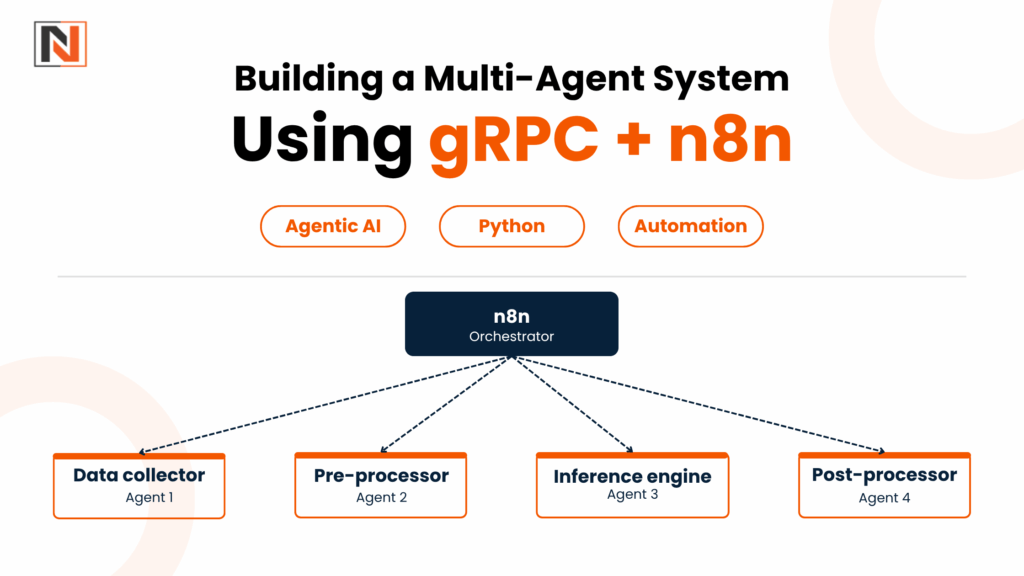
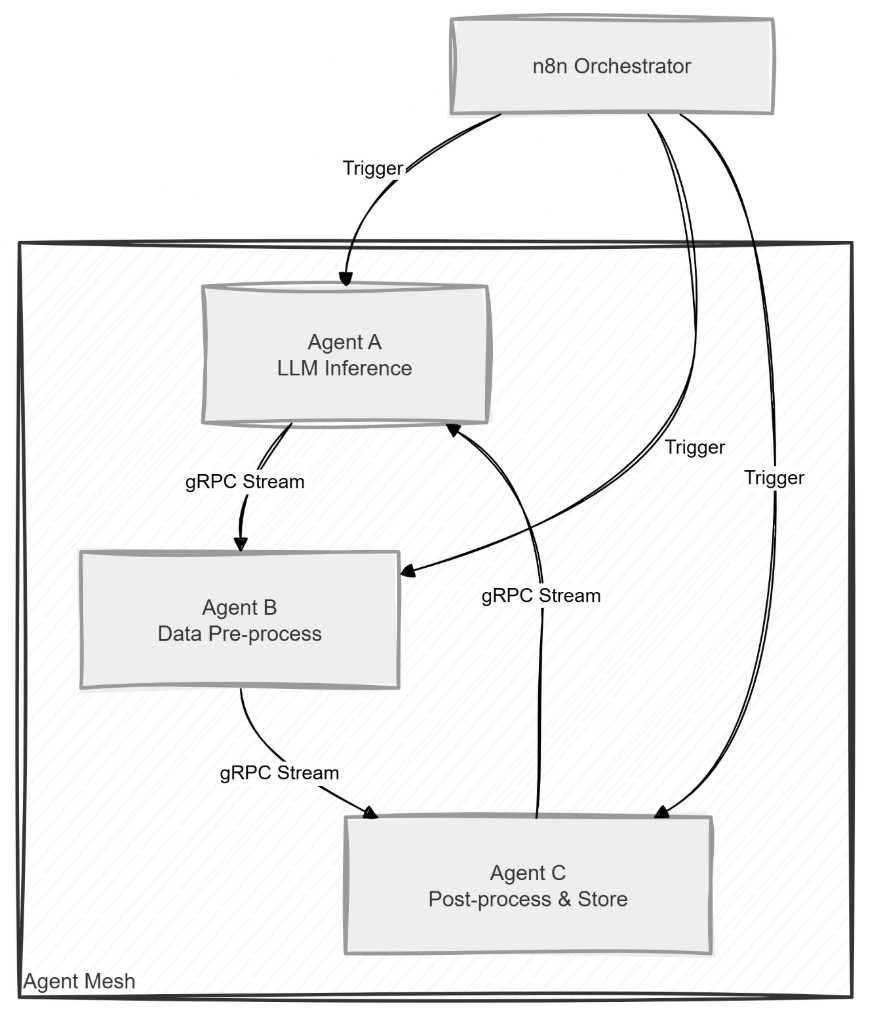
// n8n Function Node: Orchestrate two gRPC AI agents
const grpc = require(‘@grpc/grpc-js’);
const protoLoader = require(‘@grpc/proto-loader’);
const packageDef = protoLoader.loadSync(‘agent.proto’, {
keepCase: true, longs: String, enums: String, defaults: true, oneofs: true,
});
const agentProto = grpc.loadPackageDefinition(packageDef).agent;
const preprocessClient = new agentProto.AgentService(‘localhost:50051’, grpc.credentials.createInsecure());
const inferenceClient = new agentProto.AgentService(‘localhost:50052’, grpc.credentials.createInsecure());
function callAgent(client, method, request) {
return new Promise((resolve, reject) => {
client[method](request, (err, response) => {
if (err) reject(err);
else resolve(response);
});
});
}
async function orchestrate() {
try {
const preprocessed = await callAgent(preprocessClient, ‘ProcessData’, { raw: $json.input });
const result = await callAgent(inferenceClient, ‘RunInference’, { data: preprocessed.cleaned });
return [{ json: { inference: result.output } }];
} catch (error) {
throw new Error(`Agent orchestration failed: ${error.message}`);
}
}
return orchestrate();