

Introduction to Agentic Mesh and Its Challenges
What is an agentic mesh?
In recent years the term agentic mesh has moved from academic papers to production‑grade systems. At its core, an agentic mesh is a network of autonomous, purpose‑built AI agents that collaborate to solve complex problems. Each agent encapsulates a single capability—such as summarisation, entity extraction, or sentiment analysis—and communicates with its peers through well‑defined protocols. The mesh topology allows the system to dynamically route data, parallelise work, and recover from failures without a single point of control.
Imagine a newsroom that receives a breaking story, enriches it with background context, extracts key entities, and then pushes personalised alerts to multiple platforms. Instead of a monolithic pipeline that runs every step sequentially, the mesh spins up the exact agents required for that story, lets them exchange messages, and discards them when the job is finished. This on‑demand, plug‑and‑play approach is what makes modern news intelligence both fast and cost‑effective.
Challenges with monolithic AI pipelines
Traditional AI pipelines are often built as long, linear chains of micro‑services or as a single heavyweight application. While straightforward to prototype, they suffer from several drawbacks:
- Scalability bottlenecks – A single service becomes the limiting factor when traffic spikes, and horizontal scaling is hard because the whole pipeline must be duplicated.
- Tight coupling – Changing one component (e.g., swapping a summarisation model) forces downstream services to be retested, increasing the risk of regression.
- Limited fault tolerance – If any step crashes, the entire request fails, requiring expensive retry logic and manual intervention.
- Resource waste – Every request must pass through every stage, even if only a subset of capabilities is needed, leading to unnecessary compute consumption.
- Lack of temporal awareness – Traditional pipelines are typically batch-oriented and operate within fixed execution windows. They lack native support for:
- real-time event handling
- long-running workflows
- stateful retries and resumability
As a result, they struggle to react to evolving signals (e.g., breaking news, rapidly changing narratives) in a timely and reliable manner. Any attempt to add durability or real-time responsiveness often requires custom scheduling, retry logic, and state management – leading to increased system complexity.
These pain points push organisations toward a more modular, resilient architecture – precisely what an agentic mesh promises. However, moving from monolithic pipelines to a distributed mesh introduces its own set of engineering challenges: protocol design, state management, orchestration, and observability become critical concerns.
So we built an agent-first mesh architecture where:
- Orchestrator decides
- Specialists execute
- A2A connects everything
- Temporal handles durability
- OpenAI Agents SDK powers reasoning
This is not theoretical. This is what we actually built.
Designing a Scalable Multi‑Agent Architecture
Layered Architecture for Agentic Systems
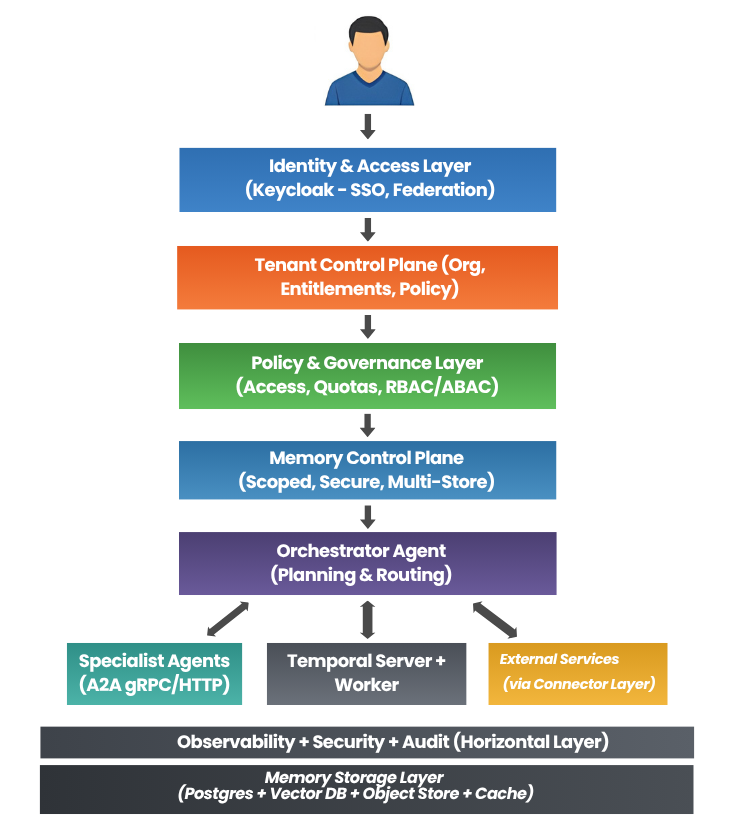
Scalability in an agentic mesh is achieved by separating concerns into distinct layers. This layered approach mirrors classic software architecture but is adapted for agent-based, AI-driven systems.
In this architecture, responsibilities are clearly divided across communication (A2A), reasoning (OpenAI Agents SDK), and durability (Temporal).
Core Layers
Identity & Access Layer
Handles:
Handles:
- authentication (SSO)
- identity federation
- token issuance
- service identity
Ensures:
- every request is authenticated
- identity context flows through the system
Tenant Control Plane
Introduces SaaS capabilities:
- tenant provisioning
- organization/workspace mapping
- entitlements and plans
- connector ownership
Ensures:
- strict isolation between tenants
- scalable multi-tenant architecture
Policy & Governance Layer
Combines:
- access control (RBAC/ABAC)
- quotas (agent, tenant, user)
- service-to-service authorization
Enforcement happens before execution, ensuring:
- controlled usage
- security
- predictable costs
Memory Control Plane
Memory is treated as a platform capability, not agent-owned.
Supports:
- session memory
- user memory
- tenant memory
- audit/provenance
Key principles:
- scoped memory (user / tenant / platform)
- privacy-first defaults
- policy-aware retrieval
- auditability
Orchestration Layer
Uses reasoning systems to:
- interpret user intent
- create execution plans
- route tasks
Transport Layer (A2A Communication)
Handles agent communication via:
- gRPC (preferred)
- HTTP JSON-RPC (fallback)
Security:
- mTLS for service-to-service trust
- JWT for identity verification
Workflow Layer (Temporal)
Temporal ensures:
- durability
- retries
- long-running workflows
- human-in-the-loop
Agent Execution Layer
Each agent:
- is independently deployable
- runs in Docker
- exposes A2A interface
- performs one responsibility
Persistence & Storage
Includes:
- Postgres (metadata, policy, tenant data)
- Vector DB (memory retrieval)
- Object storage (artifacts)
- Redis (cache/session)
Observability & Audit Layer
Ensures:
- tracing
- monitoring
- debugging
- audit logs
Secure Communication (mTLS + Tokens)
We use a dual-layer trust model:
- mTLS → verifies service identity at transport layer
- JWT tokens → carry identity, tenant, and permissions
This ensures:
- zero trust between services
- strong authentication
- secure A2A communication
Memory-Aware Execution
Unlike traditional systems:
- memory is not global
- memory is scoped
- memory access is policy-controlled
Retrieval follows:
- session
- user
- tenant
- platform
Layer Summary
| Layer | Role | Key Technologies |
|---|---|---|
| User | API entry | FastAPI |
| Identity & Access | Authentication, SSO, federation, token issuance | Keycloak, JWT |
| Tenant Control Plane | Multi-tenancy, org/workspace management, entitlements | FastAPI, Postgres |
| Policy & Governance | Access control, quotas, authorization | Redis, Postgres, Policy Service |
| Memory Control Plane | Scoped memory, retrieval, lifecycle, privacy enforcement | Postgres, Vector DB (Pinecone/Weaviate/FAISS), Redis, S3 |
| Orchestration | Planning & routing | OpenAI Agents SDK |
| Internal Agent Orchestration | Multi-step execution, branching, checkpoints | LangGraph |
| Transport | Agent communication | A2A, gRPC, HTTP JSON-RPC |
| Transport Security | Service-to-service trust | mTLS, TLS |
| Workflow | Durable execution, retries, long-running workflows | Temporal |
| Agent Execution | Domain-specific capabilities | Python services, Docker |
| Persistence | Storage & audit | Postgres, S3 / Blob Storage |
| Cache & Session | Ephemeral state, quotas, session memory | Redis |
| Event Layer (Optional) | Async pub/sub (advanced) | Redis Streams, Kafka |
| Observability & Audit | Monitoring, tracing, metrics, logging, audit | Prometheus, Grafana, OpenTelemetry, New Relic |
Key Architectural Insight
A2A handles communication.
OpenAI Agents SDK handles reasoning.
Temporal handles durability.
By keeping these concerns separate:
- you avoid tight coupling
- you prevent over-engineering
- and you retain flexibility to evolve each layer independently
For most systems, this minimal layered design is sufficient. End-to-end observability ensures full visibility into agent decisions, workflows, and system performance in real time. Additional layers like message buses should only be introduced when scaling demands it.
Key technologies enabling scalability
- Docker – Containerisation guarantees that every agent runs in an isolated, reproducible environment. It also simplifies horizontal scaling via orchestration platforms like Kubernetes.
- gRPC – Binary protocol that reduces payload size and latency, crucial for real‑time mesh interactions.
- Temporal – Provides stateful workflow management with built‑in durability, making it easy to recover from failures without custom retry logic.
- Postgres – Relational store for metadata, job queues, and audit logs. Its ACID guarantees help maintain consistency across distributed agents.
- OpenAI Agents SDK – Offers high‑level abstractions for creating and registering agents, handling authentication, and exposing a unified API surface.
- Pydantic – Validates data structures in Python, preventing malformed messages from propagating through the mesh.
Together, these tools create a robust foundation that can handle the unpredictable load patterns typical of news intelligence pipelines.
Implementing Temporal Workflows for Durability and Orchestration
Introduction to Temporal.io and its applications
Temporal is an open‑source orchestration platform that treats workflows as first‑class citizens. Unlike traditional job schedulers, Temporal persists every state transition to durable storage, enabling automatic replay after crashes. For a news intelligence mesh, Temporal can manage:
- Continuous monitoring of RSS feeds, social media streams, and internal data sources.
- Retry policies for flaky third‑party APIs (e.g., price‑check services or sentiment analysis providers).
- Human‑in‑the‑loop approvals when a story requires editorial sign‑off before distribution.
Because workflows are defined in code, developers can use familiar languages – Python, Go, orJava – to express complex branching logic without learning a new DSL.
Durability and retry mechanisms in Temporal workflows
Temporal guarantees that no work is lost, even if the underlying worker process crashes. Each activity (e.g., “fetch article”, “run summarisation”) is recorded in a durable event store. If a worker dies, Temporal re‑queues the activity on a healthy worker, applying exponential back‑off and custom retry policies.
Below is a simplified flowchart that illustrates how Temporal ensures durability and automatic retries for a continuous monitoring workflow that watches a news source, extracts entities, and stores results in Postgres.
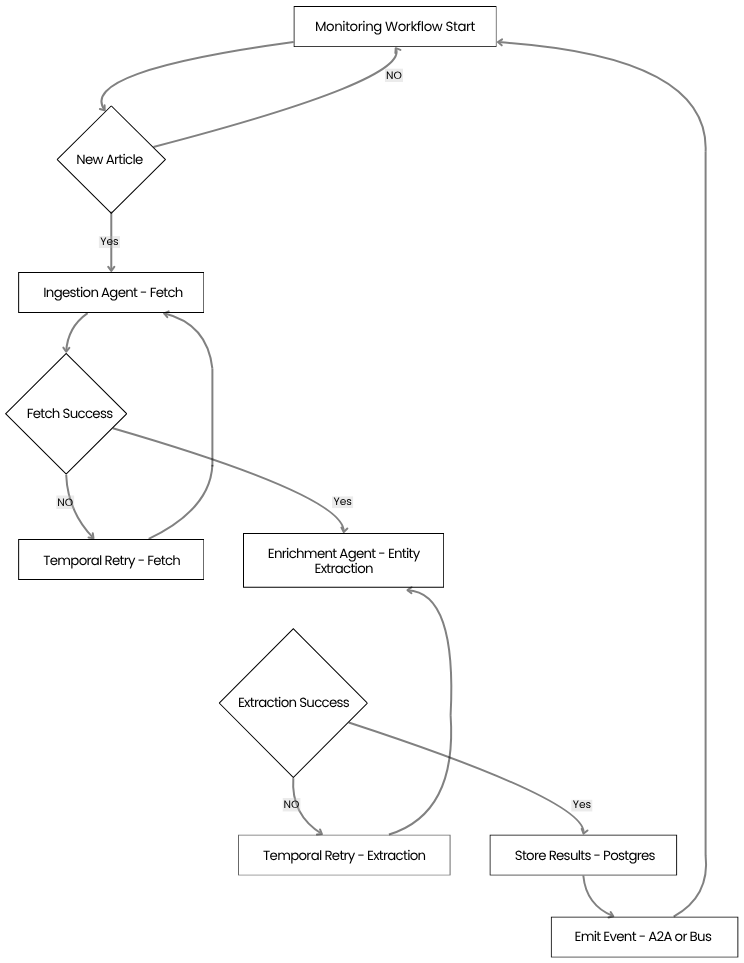
Temporal’s built‑in visibility tools let operators monitor each step, see retry counts, and inspect historic runs. This level of observability is essential for production‑grade news pipelines where missed alerts can have real‑world impact.
Building a News Intelligence Workflow with Agents
Breaking down a user query workflow
When a journalist or analyst submits a query—“What are the emerging trends in renewable energy investments in Europe?”—the mesh must orchestrate several agents: a retrieval agent to gather sources, a summarisation agent, an entity‑linking agent, and finally a presentation agent that formats the answer for the UI. The following flowchart maps this end‑to‑end process.

Each arrow represents an A2A call over gRPC. The Presentation Agent is a lightweight FastAPI service that formats the final JSON payload and streams it back to the front‑end. Because every step is an independent, containerised agent, the system can scale each component independently based on load.
Key considerations for designing agent boundaries
Designing clear boundaries prevents the mesh from devolving into a tangled web of responsibilities. Below is a checklist that helps architects decide where one agent should stop and another begin.
| Component | Responsibility | Design Considerations |
|---|---|---|
| Retrieval Agent | Query external sources, cache results | Use Docker for isolation; respect rate limits; |
| Summarisation Agent | Condense long texts into concise abstracts | Keep model size manageable; expose temperature & max‑tokens as parameters. |
| Entity‑Linking Agent | Identify entities and link to knowledge graph | Ensure deterministic output; store mappings in Postgres for reuse. |
| Presentation Agent | Format and deliver results to UI | Implement FastAPI endpoints; validate schema with Pydantic; support streaming responses. |
| Orchestration Layer | Coordinate workflow steps, handle retries | Leverage Temporal for durability; define retry policies per activity. |
By answering these questions – What data does the component own? How does it communicate? What are its scaling requirements? – You can create a mesh that is both flexible and maintainable.
Practical Implementation: Code Examples and Tools
Planner using OpenAI Agents SDK (Reasoning Layer)
This is your brain, not your transport.
from __future__ import annotations
from pydantic import BaseModel
from agents import Agent, Runner
class ExecutionPlan(BaseModel):
mode: str
reason: str
target_agent: str | None = None
planner_agent = Agent(
name=“News Planner”,
instructions=(
“You are a planner for a news intelligence system.\n“
“Return a structured execution plan.\n“
“Allowed modes: chat, remote_agent, workflow.\n“
“Use target_agent=’summariser’ for summarisation requests.\n“
“Use mode=’workflow’ for full news intelligence requests.”
),
output_type=ExecutionPlan,
)
async def build_plan(message: str) -> ExecutionPlan:
result = await Runner.run(planner_agent, message)
return result.final_output
Why this matters
- Uses OpenAI Agents SDK correctly
- Produces structured execution plans
- Keeps reasoning separate from transport and workflows
A2A gRPC Call (Communication Layer)
This is how your orchestrator talks to a summariser agent.
from __future__ import annotations
import asyncio
from a2a.client import A2AClient
from a2a.types import Message, Part, Role, TextPart
async def call_summariser_grpc(text: str) -> str:
client = A2AClient(
url=”grpc://localhost:50051″,
)
request = Message(
role=Role.user,
parts=[
Part(
root=TextPart(
text=f”Summarise this article in 150 tokens or less:\n\n{text}”
)
)
],
)
final_text_parts: list[str] = []
async for event in client.send_message(request):
if isinstance(event, Message):
for part in event.parts:
if isinstance(part.root, TextPart):
final_text_parts.append(part.root.text)
return “”.join(final_text_parts).strip()
if __name__ == “__main__”:
sample = “Renewable energy investments are rapidly growing across Europe.”
result = asyncio.run(call_summariser_grpc(sample))
print(“Summary:”, result)
This call uses the A2A SDK’s gRPC transport to send a structured Message to the remote summariser agent and stream back the response.
Temporal Workflow (Durable Orchestration Layer)
This is your news intelligence pipeline.
from __future__ import annotations
from datetime import timedelta
from temporalio import workflow
@workflow.defn
class NewsIntelligenceWorkflow:
@workflow.run
async def run(self, query: str) -> str:
# Step 1: Retrieve articles
article = await workflow.execute_activity(
“retrieval_agent.fetch“,
query,
schedule_to_close_timeout=timedelta(seconds=30),
)
# Step 2: Summarise content (via summariser agent)
summary = await workflow.execute_activity(
“summarisation_agent.summarise“,
article,
schedule_to_close_timeout=timedelta(seconds=30),
)
# Step 3: Entity linking / enrichment
enriched = await workflow.execute_activity(
“entity_link_agent.link“,
summary,
schedule_to_close_timeout=timedelta(seconds=30),
)
# Step 4: Persist results
await workflow.execute_activity(
“results_store.save“,
{“query”: query, “answer”: enriched},
schedule_to_close_timeout=timedelta(seconds=15),
)
return enriched
Use OpenAI Agents SDK for reasoning and planning, A2A for communication between services, and Temporal for durability, retries, and long-running workflows. That separation keeps the system clean: the SDK thinks, A2A connects, and Temporal remembers. The Agents SDK’s documented primitives center on agents, runners, tools, handoffs, and typed outputs, which makes it a strong fit for planner and narrative layers rather than transport or persistence.
Future Considerations and Best Practices
Balancing flexibility and coupling in agent systems
An overly flexible mesh can become a “spaghetti” of services where every agent knows about many others. To avoid this, adopt domain‑driven boundaries: group related capabilities into a bounded context and expose only the minimal interface required for collaboration. Use versioned A2A contracts so that downstream agents can continue operating when an upstream agent evolves. Monitoring tools (e.g., OpenTelemetry) should be integrated at the transport layer to surface latency spikes and coupling violations early.
Avoiding over‑engineering in agentic mesh design
While the allure of a fully decoupled mesh is strong, not every use‑case needs the full stack. For low‑traffic internal tools, a simple local execution path may suffice. Reserve Temporal and heavyweight gRPC setups for scenarios that truly benefit from durability, high concurrency, or multi‑region redundancy. Start with a minimal viable mesh, then iteratively introduce layers—adding a message bus, containerisation, or orchestration only when performance metrics justify the added complexity.
By adhering to the principles outlined above—clear A2A contracts, layered scalability, durable Temporal workflows, and pragmatic engineering—you can build a production‑grade news intelligence platform that scales with demand, recovers from failures, and remains adaptable to future AI breakthroughs. The combination of Python, FastAPI, A2A SDK, gRPC, Temporal, Postgres, OpenAI Agents SDK, Pydantic, and Docker provides a powerful, vendor‑agnostic toolkit to turn the vision of an agentic mesh into reality.
Frequently Asked Questions
What is the Agent-to-Agent (A2A) communication protocol?
The Agent-to-Agent (A2A) protocol – implemented using the Google A2A protocol SDK – standardizes how agents communicate over gRPC and HTTP JSON-RPC.
It enables secure, structured, and interoperable communication between independent agents.
Importantly, A2A is responsible only for transport and message exchange.
All reasoning, planning, and decision-making are handled separately by the orchestrator layer using tools such as the OpenAI Agents SDK.
How do you build scalable and secure multi-agent systems?
Scalable enterprise-grade systems are built using a control-plane-driven architecture that separates responsibilities across layers:
- Identity & Access Layer – Authentication, SSO, federation (e.g., Keycloak)
- Tenant Control Plane – Organization, entitlements, multi-tenancy
- Policy & Governance Layer – Access control, quotas, RBAC/ABAC enforcement
- Memory Control Plane – Scoped, secure, multi-store memory management
- Orchestration Layer – Dynamic planning and routing of tasks
- Transport Layer – A2A (gRPC / HTTP JSON-RPC)
- Workflow Layer – Durable execution and retries (e.g., Temporal)
- Observability Layer – Monitoring, tracing, auditing
This separation ensures scalability, security, and operational control without tight coupling.
What role does Temporal play in this architecture?
Temporal acts as the workflow execution backbone of the system.
It provides:
- Durable execution of long-running processes
- Built-in retries and failure handling
- State persistence and recovery
- Visibility into workflow execution
In this architecture, Temporal is not embedded inside agents, but operates as a separate workflow layer that agents and orchestrators leverage when reliability is required.
What is the role of the control planes (Tenant, Policy, Memory)?
The introduction of control planes is a key evolution in the architecture:
- Tenant Control Plane → Manages organizations, users, and entitlements
- Policy & Governance Layer → Enforces access, quotas, and compliance
- Memory Control Plane → Governs how memory is stored, accessed, and shared across agents
Together, these layers ensure the system is:
- Multi-tenant by design
- Secure and compliant
- Consistent in behavior across agents
What are the benefits of this agentic mesh architecture for enterprises?
This architecture delivers:
- Strong governance → Built-in identity, policy, and audit layers
- Scalability → Independent agents scale horizontally
- Fault tolerance → Temporal ensures workflow reliability
- Flexibility → Dynamic routing via orchestrator
- Security-first design → Policy and memory isolation baked in
- Observability → End-to-end tracing and monitoring
This makes it highly suitable for complex enterprise use cases such as insurance intelligence, financial analytics, and multi-agent automation platforms.
What tools and technologies are used in this architecture?
The system leverages a modern, production-ready stack:
- Identity & Access → Keycloak
- Agent Orchestration → OpenAI Agents SDK
- Agent Communication → Google A2A protocol (gRPC, HTTP JSON-RPC)
- Workflow Orchestration → Temporal
- Storage Layer → Postgres, Vector DB, Object Store, Cache
- Containerization → Docker
- Observability → Prometheus, Grafana, OpenTelemetry